Problème rencontré : le script fonctionne parfaitement, au détail près qu’il génère six tableaux au lieu de quatre (le dossier URLS contenant bel et bien quatre fichiers d’urls), dont deux doublons.
Solution : afficher les fichiers cachés dans le dossier URLS… Ô surprise, deux fichiers s’étaient immiscés là, des doublons de mes fichiers d’urls.

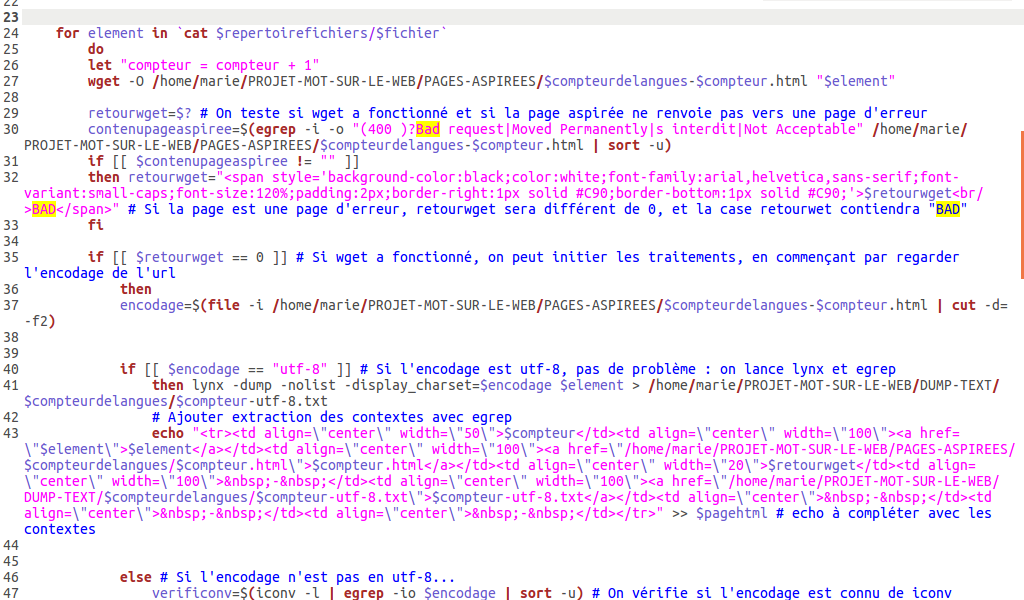
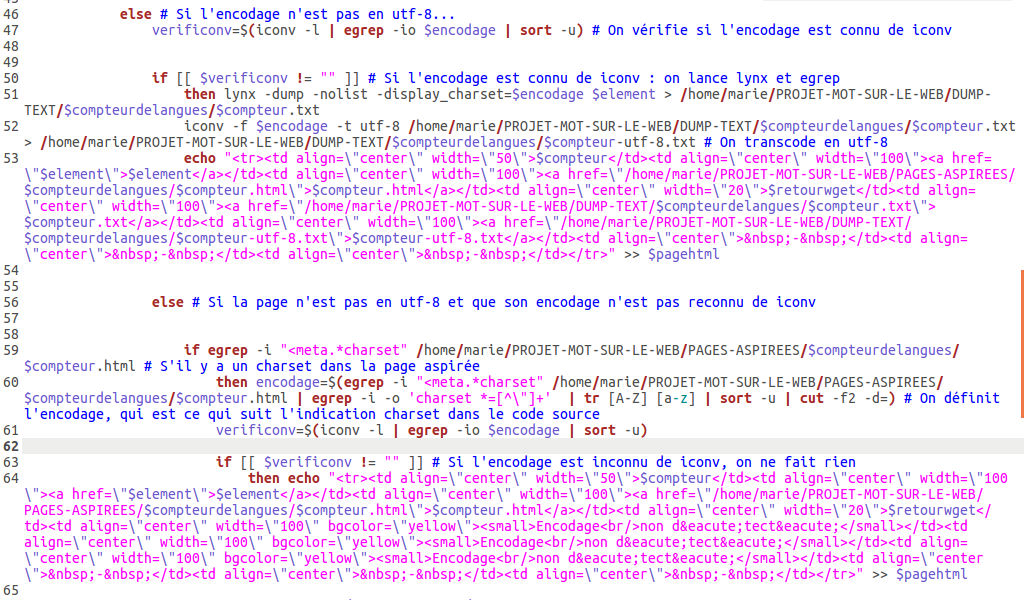


Idée lumineuse : préciser l’encodage de notre propre page html…
Après une quantité raisonnable de déboires, le script fonctionne et on obtient de splendides tableaux :
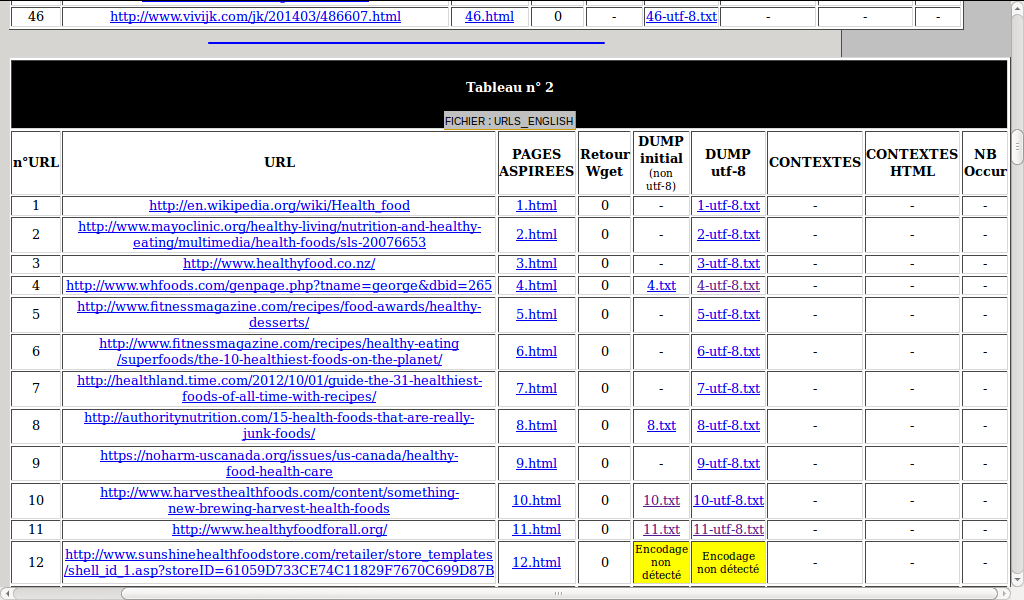
Problème : le chinois… Iconv fonctionne mal : il ne semble pas reconnaître l’encodage. Du coup, l’opération de transcodage fonctionne également mal, et les pages censées être en utf-8 sont illisibles (même par un sinophone…). A suivre.
Bonus : Nous attendons avec impatience le petit programme de notre chère collègue Catherine, qui va permettre un meilleur tri des urls : celles qu’on accepte et celles qui correspondent à des pages d’erreur. Protocole : regarder la taille des fichiers texte contenant le dump des urls ; si elle est inférieure à un seuil que nous aurons fixé (2 octets, ce me semble), l’url est out. Cela évitera quelques bugs rencontrés en chemin. Exemple : certaines pages parfaitement acceptables et même en utf-8 (ô joie), ont été étiquetées d’un “BAD” sans appel et reléguées dans la catégorie des pages d’erreur.
